


Friday, May 9, 2025
Bernhard Palsson, Ph.D., will present "What are iModulons?" on May 9, 2025, from 12:00 p.m.–1:00p.m. EDT.
About the Seminar
The first microbial genome sequences appeared in the mid to late 1990s. In the 2000s, computational biology at the genome-scale arose through the reconstruction of metabolic networks based on functional gene annotation. In the late 2000s, the cost of DNA sequencing dropped massively, leading to rapidly expanding data bases of microbial genome sequences and microbial transcriptomes. These data sets could be knowledge-enriched and decomposed into coherently functioning sets of genes using machine learning methods. A growing number of data types can be processed in a similar fashion. Multiple data types can now be made interoperable based on known mechanisms and molecular functions. The 2020s are likely to see an accelerating fine-grained understanding of microbial physiology.
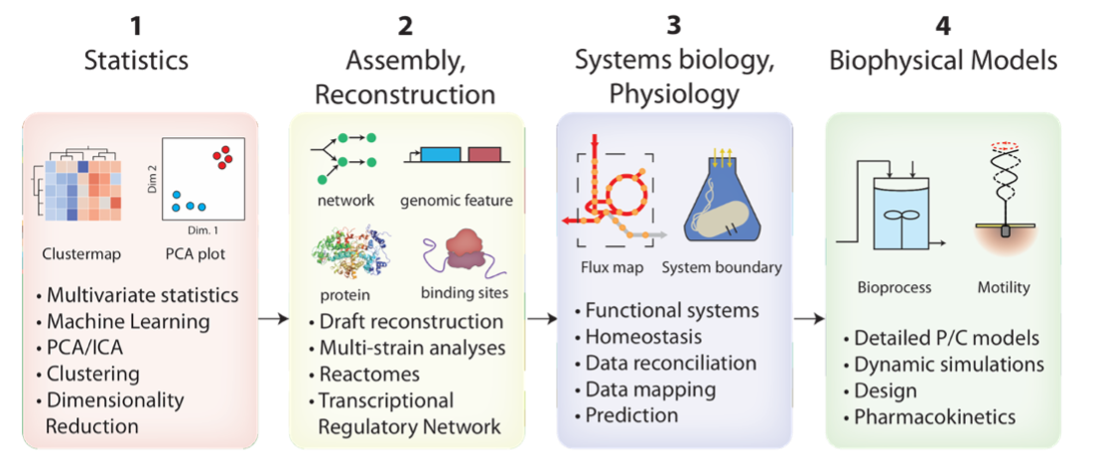
Analysis of large biological data sets can take place at four levels. At level 1 we perform multi-variate statistics, at level 2 knowledge-enrichment of large data sets, at level 3 systems biology and computational modeling, and at level 4 detailed biophysical modeling. Levels 1 and 4 are well developed in the literature. The history of genome-scale models, level 3, is about 20 years old with much progress made. Level 2 is the least developed and is focused on knowledge mapping and the use of machine learning and explanatory AI.
This talk will focus on progress at levels 2 with transcriptomes. Large compendia of high-quality RNAseq profiles can now be decomposed using Independent Component Analysis (ICA). ICA identifies independently modulated sets of genes, called iModulons. This talk will show the uses of iModulons for metabolic engineering and bioprocess development: including cross-species transfer of iModulons, Media composition, expression of heterologous genes, and y-gene discovery.
About the Speaker
Bernhard Palsson, Ph.D., Director/Principal Investigator, Departments of Bioengineering and Pediatrics, University of California, San Diego
About the Seminar Series
The seminar is open to the public and registration is required each month. Individuals who need interpreting services and/or other reasonable accommodations to participate in this event should contact Allison Hurst at 301-670-4990. Requests should be made at least five days in advance of the event.
The National Institutes of Health (NIH) Office of Data Science Strategy hosts this seminar series to highlight examples of data sharing and reuse on the second Friday of each month at noon ET. The monthly series highlights researchers who have taken existing data and found clever ways to reuse the data or generate new findings. A different NIH institute or center will also share its data science activities each month.