


The Expanding and Overlapping Roles of Institutional and Generalist Repositories: Building an Interoperable Data Repository Ecosystem Together
Tuesday, June 17, 2025
External News link
Tuesday, June 17, 2025
Thursday, July 10, 2025
Wednesday, July 16, 2025
View Building Skills with Generalist Repositories: An Update on the Carpentries + GREI Collaboration
Wednesday, July 23, 2025
Friday, September 12, 2025
Arthur W. Toga, Ph.D., will present "Data Sharing in the Real World" from 12:00 p.m.–1:00 p.m. EDT.
Data sharing in scientific research is widely acknowledged as crucial for accelerating progress and innovation. Mandates from funders, including the NIH's updated Data Sharing Policy, have been beneficial in promoting data sharing. This talk will cover several of the multifaceted challenges of incentivizing data sharing and the complex interplay of factors involved. There are many issues, such as the motivations of various stakeholders, including funders, investigators, and data users, highlighting the differences in perspectives and concerns. Also covered is the importance of guidelines, such as the FAIR principles, in promoting good data management practices but acknowledge the practical and sociological challenges in implementation. This presentation also examines the impact of infrastructure on data sharing effectiveness, emphasizing the need for viable and affordable systems that support efficient data discovery, access, and analysis.
Arthur W. Toga, Ph.D. Provost Professor of Ophthalmology, Neurology, Psychiatry and the Behavioral Sciences, Radiology and Biomedical Engineering, director of the USC Mark and Mary Stevens Institute of Neuroimaging and Informatics and director of the Laboratory of Neuro Imaging (LONI)
Dr. Toga’s work involves neuroimaging, informatics, AI applications in neuroscience, mapping brain structure and function, and brain atlasing. His research focuses on neurodegenerative disease and specifically works on Alzheimer’s disease. Funded by the National Institutes of Health (NIH), the Alzheimer’s Association, the Michael J Fox Foundation among others, as well as industry partners, LONI houses one of the larger computing facilities and brain image repositories in the world.
He is an author or co-author of more than 1100 peer-reviewed papers, 1500 abstracts and 80 book chapters or books. He is the founding editor of the journal NeuroImage. Dr. Toga has received numerous awards, including the Pioneer in Medicine Award, Smithsonian Award for Scientific Innovation and Giovanni DiChiro Award for Outstanding Scientific Research. He holds the Ghada Irani chair in Neuroscience and has been one of the world’s top researchers on the AD Scientific Index, Top 200 Best Scientists in Neuroscience on Research.com, and listed as one of Thomson Reuters' and Clarivate Highly Cited Researchers for many years.
The seminar is open to the public and registration is required each month. Individuals who need interpreting services and/or other reasonable accommodations to participate in this event should contact Allison Hurst at 301-670-4990. Requests should be made at least five days in advance of the event.
The National Institutes of Health (NIH) Office of Data Science Strategy hosts this seminar series to highlight examples of data sharing and reuse on the second Friday of each month at noon ET. The monthly series highlights researchers who have taken existing data and found clever ways to reuse the data or generate new findings. A different NIH institute or center will also share its data science activities each month.
Tuesday, August 19, 2025

By: Dr. Susan Gregurick, Associate Director of Data Science, NIH
Welcome to the August 2025 Director’s Corner! I’m excited to share updates from the NIH Office of Data Science Strategy (ODSS) as we work to build a modernized, integrated, and FAIR (Findable, Accessible, Interoperable, Reusable) biomedical data ecosystem. This month, I’m spotlighting the innovative work of the AIM-AHEAD program, which is transforming biomedical research through artificial intelligence and machine learning (AI/ML).
On the heels of the 2025 AIM-AHEAD Annual Meeting, July 7-10 in Dallas, TX, there are many success stories to highlight from the NIH’s AIM-AHEAD initiative. The annual meeting brought together over 430 vibrant community members, including awardees, trainees, fellows, stakeholders, mentors, and NIH officials from across the country, for an engaging in-person conference that highlighted the program's growing impact in AI health research and the development of AI talent. The event featured dynamic panel discussions, collaborative breakout sessions, and rich networking opportunities that fostered meaningful connections and knowledge exchange. With over 200 research posters presented, attendees witnessed the depth and innovation emerging from AIM-AHEAD initiatives.

The AIM-AHEAD Program for Artificial Intelligence Readiness (PAIR) empowers emerging institutions to lead in AI-driven health research through interdisciplinary training, coaching, mentorship, grantsmanship, leveraging AIM-AHEAD resources and support. A standout success is the Responsible AI Health Lab at the University of Washington Tacoma, co-led by PAIR awardee Dr. Martine De Cock. With AIM-AHEAD’s support, the team secured an NSF National Artificial Intelligence Research Resources (NAIRR) pilot award to advance synthetic data generation using real-world datasets, paving the way for high-impact AI tools in healthcare.
Another key success story emerging from the AIM-AHEAD program is its ability to empower clinicians to integrate AI into their daily practice. Through hands-on projects, personalized mentorship, and real-world applications, the program equips healthcare professionals to drive meaningful and impactful AI adoption at the frontlines of care.
For example, Yui Nishiike, a Nurse Practitioner and the Chief Medical Information Officer at LifeLong Medical Care—and one of the AIM-AHEAD Leadership Fellowship awardees—exemplifies the power of clinician-led innovation. With the support of expert mentorship, she developed an AI-driven risk model that flags patients at high risk of missing appointments or prescriptions-critical factors contributing to care gaps. By leveraging enhanced electronic health records (EHR) and AI, Nishiike is making new technologies more responsive to the unique needs of patients served by Community Health Centers like LifeLong.
At this year’s AIM-AHEAD annual meeting, one standout project came from Dr. Jay Patel, a Dentist and Clinical Informaticist from Temple University, an AIM-AHEAD Clinicians Leading Ingenuity IN Al Quality (CLINAQ) Fellowship awardee. His innovative work focuses on whole-person care by integrating EHR and dental health records-two systems that have traditionally operated in isolation. By bridging this divide, Dr. Patel’s project enables clinicians to develop a more comprehensive view of a patient’s health, including oral health alongside conditions like cancer and other medical issues. His work not only highlights the power of data integration but also reinforces the importance of treating patients as whole individuals.
Lastly, the AIM-AHEAD Program also established meaningful partnerships with American Indian Communities and the American Indian Higher Education Consortium (AIHEC). The partnership includes efforts to support the next generation of American Indian data science and AI talents, as well as build capacity at Tribal Colleges and Universities (TCUs). Through their stories, they demystify the path to careers in AI/ML, sharing the steps that led them to their current roles, the challenges they faced, and the individuals or programs that supported them along the way. Each scientist discusses their personal and professional motivations for entering the field, as well as their visions for the future of AI and data science in American Indian communities.
The above-mentioned examples underscore AIM-AHEAD’s influence in nurturing AI talents, advancing health research through AI and affirm its critical role in shaping the future of AI and health research nationwide.
Friday, August 8, 2025
Jay Patel, Ph.D., will present "From Silos to Synergy: Linking Dental and Medical Data to Advance Precision Oral Health" from 12:00 p.m.–1:00 p.m. EDT.
Dr. Jay Patel is a clinician-scientist uniquely trained in both dentistry and informatics/computer science. As the Director of Artificial Intelligence (AI), Data Science, and Informatics, he leads efforts to reuse and integrate real-world data including linked medical-dental electronic health records (EHRs/EDRs) and social determinants of health (SDOH) to develop clinical decision support systems that enable early diagnosis, prediction, and prevention of disease. Dr. Patel has engineered AI-based algorithms that connect disparate clinical records and developed more than 40 natural language processing pipelines to extract diagnostic and phenotypic information from free-text clinical notes. Moreover, he has developed algorithms that can predict diagnoses using metadata. These efforts exemplify “clever ways to reuse data,” aligning directly with the mission of the NIH Data Sharing and Reuse Seminar Series to showcase innovative uses of existing datasets.
Dr. Patel has developed 13 CDSS using multi-modal datasets. See below the functionality of some of the CDSS and their alignment with the NIH’s Data Sharing and Reuse mission.
Linked dataset infrastructure: Dr. Patel has created a unique dataset of 147,382 patients with linked EHR/EDR, demonstrating impactful reuse of EHR data to explore oral-systemic health relationships and treatment outcomes.
Risk assessment models: He has developed risk assessment models that repurpose longitudinal EHR data to predict the future risk of oral cancer, periodontal disease, and dental caries.
Geospatial analytics: He has applied geospatial analytics to reuse patient and community-level data, mapping oral health trends across Philadelphia and identifying area-level factors contributing to oral health disparities.
Feature reduction tool: Dr. Patel has developed feature reduction tools that reuse complex EHR data to condense hundreds of clinical variables into streamlined predictors for statistical and machine learning models.
Real-time health information exchange (HIE): The HIE tool enhances data Accessibility and Interoperability between medical and dental care teams by enabling real-time viewing of diagnoses and oral health status across systems.
Natural language processing: The NLP programs make unstructured clinical notes Findable and Reusable by converting them into structured, machine-readable formats that can be shared and reused across studies.
Feature reduction tools: The feature reduction tools improve the reusability and interoperability by creating streamlined variable sets that can be applied across machine learning pipelines and clinical research.
Diagnostic models: Dr. Patel has developed both diagnostic and prognostic prediction models by analyzing multimodal datasets, including linked medical-dental EHRs, social determinants of health (SDOH), and radiographic imaging. These AI-powered systems provide objective, automated diagnoses for periodontal disease and dental caries. By integrating diverse data sources, the models enable interdisciplinary teams to assess risk factors comprehensively and support a holistic approach to patient care, moving beyond siloed, condition-specific treatment.
Risk assessment models: Dr. Patel’s risk assessment models help physicians assess patients’ oral health risks and dentists evaluate systemic health risks. These models identify high-risk patients, enabling both disciplines to implement timely, preventive care strategies and improve overall health outcomes.
Dr. Patel has made significant scholarly contributions to the dental AI community, serving as Principal Investigator on NIH K08, New Jersey Health Foundation (NJHF), and CareQuest grants. He also leads the AI-specific aim as a Co-Investigator on a U01 award. His work has resulted in 54 peer-reviewed publications and 47 conference abstracts across dental, informatics, and computer science journals.
Dr. Patel is the principal investigator on multiple NIH-NIDCR grants, including a K08 and a U01, and holds additional funding from foundations such as Robert Wood Johnson, William Butler, New Jersey Health, and CareQuest. His team has published over 41 peer-reviewed articles and 38 conference abstracts in dental AI and holds a U.S. patent on algorithmic linking of health records. He has also been recognized with prestigious awards, including the AADOCR William Clark Fellowship, William Bulter Award, MIND the FUTURE, and the American Dental Association's David Whiston Leadership Award for his pioneering work in dental AI.
Jay Patel, Ph.D. Clinician-scientist and Director of AI, Data Science, and Informatics at Temple University Kornberg School of Dentistry
Dr. Jay Patel is a clinician-scientist and Director of AI, Data Science, and Informatics at Temple University Kornberg School of Dentistry. He is among the few in the U.S. formally trained in both dentistry and informatics/computer science. His research focuses on reusing and integrating real-world data, including linked medical-dental electronic health records (EHR/EDR) and social determinants of health (SDOH), to develop clinical decision support systems (CDSS) for early diagnosis and prevention.
Dr. Patel has created a linked dataset of over 147,000 patients and developed 13 CDSS tools that reuse multimodal data for risk assessment, diagnosis, and health information exchange. His work exemplifies the NIH’s mission to promote creative reuse of data, alignment with FAIR data principles, and cross-disciplinary innovation in AI and health informatics. Examples include algorithms for real-time medical-dental data sharing, predictive models for oral cancer and periodontal disease, geospatial analyses of health disparities, and NLP pipelines that transform unstructured clinical notes into reusable datasets.
He has served as PI and Co-I on multiple NIH-NIDCR and foundation grants (K08, U01, NJHF, CareQuest), published over 50 peer-reviewed papers, and holds a U.S. patent. He has been honored with awards such as the ADA David Whiston Leadership Award and the AADOCR William Clark Fellowship for his leadership in dental AI.
The seminar is open to the public and registration is required each month. Individuals who need interpreting services and/or other reasonable accommodations to participate in this event should contact Allison Hurst at 301-670-4990. Requests should be made at least five days in advance of the event.
The National Institutes of Health (NIH) Office of Data Science Strategy hosts this seminar series to highlight examples of data sharing and reuse on the second Friday of each month at noon ET. The monthly series highlights researchers who have taken existing data and found clever ways to reuse the data or generate new findings. A different NIH institute or center will also share its data science activities each month.
Tuesday, July 1, 2025

By: Dr. Susan Gregurick, Associate Director of Data Science, NIH, and Hsinyi (Steve) Tsang, PhD, Clinical Informatics Lead, Office of Data Science Strategy, NIH
Imagine you are doing a longitudinal study on food allergy prevalence and severity in children. You want to understand if there have been any noticeable changes in allergy patterns and reactions going back 5, 10, and 15 years. As a researcher working with the National Institutes of Health (NIH), you have access to a lot of data about food allergies—which is great because you need a lot of data for your study.
But there is a problem: The data comes from NIH studies and different institutions nationwide. And, the researchers conducting these earlier studies used different methods to document and classify allergic reactions, making what should have been a relatively straightforward task complicated. Now, you need to figure out how to harmonize data where some studies used numerical severity scales, others used descriptive categories (i.e., mild/moderate/severe), and still others focused on specific clinical manifestations like IgE levels and skin test wheal size. Unfortunately, this is a very real headache for many biomedical researchers. Fortunately, it's a headache that NIH is trying to fix, and we're using generative artificial intelligence (GenAI) to help us do it!
At the core of this challenge is a lack of Common Data Elements (CDEs). CDEs are building blocks for research studies that ensure biomedical data is FAIR (Findable, Accessible, Interoperable, and Reusable). In practice, this means researchers ask the same question about allergy symptoms, generating the same type of data, or ensuring saved data can be accessed by different types of computer operating systems.
Promoting wider usage of CDEs is foundational to the work of NIH’s Office of Data Science Strategy (ODSS) and plays a central role in the final 2025-2030 NIH Strategic Plan for Data Science. The strategic plan highlights the need to create minimal sets of consistent and computable CDEs that support data integration across studies and repositories. It calls out programs that are already championing CDEs, such as the Mobile At-Home Reporting through Standards (MARS) and the Helping to End Addiction Long-Term (HEAL) initiative. It also emphasizes ongoing efforts to expand the usage of CDEs, including the NIH CDE Repository, NCI’s Enterprise Vocabulary Services, and the Cancer Data Standards Registry and Repository (caDSR). The strategic plan reaffirms NIH’s commitment to making CDEs a core aspect of our research enterprise.
NIH is not alone in pushing for broader adoption of CDEs. Congress appropriated funds in Fiscal Year 2024 that directed NIH and ODSS to “encourage development and use of CDEs in disease areas where they currently do not exist.” In response, ODSS did a public workshop and sent out a request for information to engage the research community on the matter of CDEs. ODSS also co-funded projects with NIH Institutes and Centers on a variety of diseases and disease areas, including chronic diseases, childhood diseases, and neurological diseases.
In parallel, ODSS sought to understand the extent of NIH’s existing efforts to promote the adoption and usage of CDEs across the entire research ecosystem. Conducting a landscape analysis across such a vast biomedical field is nearly impossible, but we leveraged the power of GenAI to help with the task.
For this landscape analysis, ODSS used GenAI to rapidly synthesize large amounts of data, taking a vast landscape and making it bite-sized for easier analysis. This is partly possible because GenAI’s predictive modeling capabilities helped streamline the analysis by anticipating patterns in publications. This approach enabled the ODSS team to categorize and identify areas of focus for approximately 145 publications that leveraged CDEs—dating back to 1978.
For this landscape analysis, the ODSS team utilized the National Institute of Allergy and Infectious Diseases’ (NIAID) government-approved GenAI Platform, DocBot. It is built on Microsoft’s implementation of OpenAI’s AI model, hosted within NIH’s Azure environment, and accessible through STRIDES. DocBot excels at reading documents and providing answers through conversational chats with users. DocBot reviewed publications and notices of funding opportunities (NOFOs) for this analysis, while the human team members reviewed awards. The team also supported the AI by providing frameworks and occasional interventions to ensure accurate data analysis. And finally, the team ensured all the data processed by the GenAI was publicly available, open access, and free of any Personally Identifiable Information (PII) or Protected Health Information (PHI). This approach allowed the team to look at the landscape from multiple perspectives, including by scientific topic, funding institute, and even fiscal year.
The preliminary findings revealed a fuller picture of CDE usage at NIH, calling out interesting trends in our work with CDEs to date and potential areas for further investment in the future (and with alignment to the NIH Strategic Plan for Data Science). So far, funding and awards for projects that use CDEs are cyclical, with a marked increase in the last 10 years (Figure 1). Additionally, most of the funding has been awarded to core facilities or data coordinating centers, meaning research projects where the data must be shared among NIH-supported researchers (Figure 2).
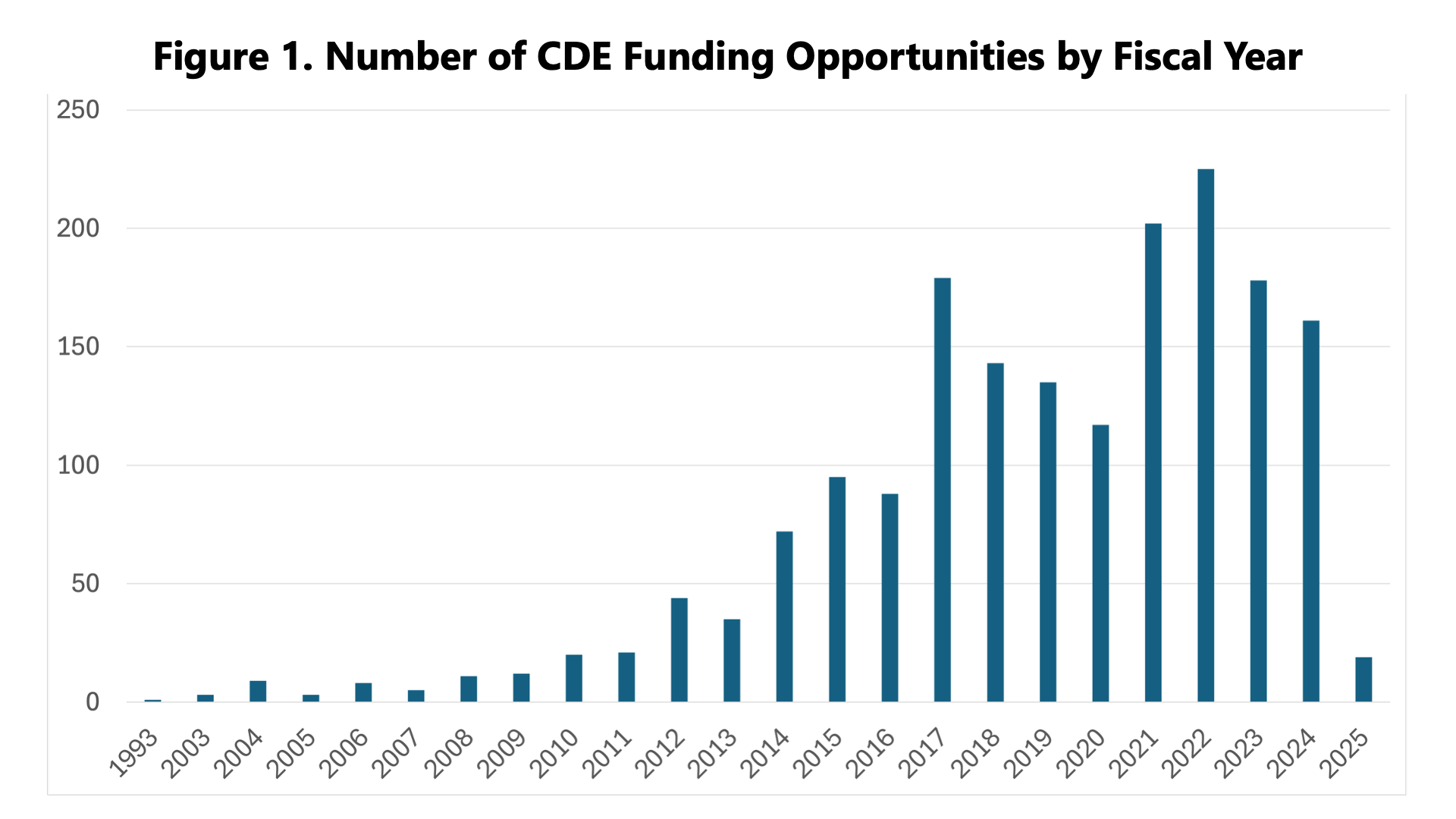
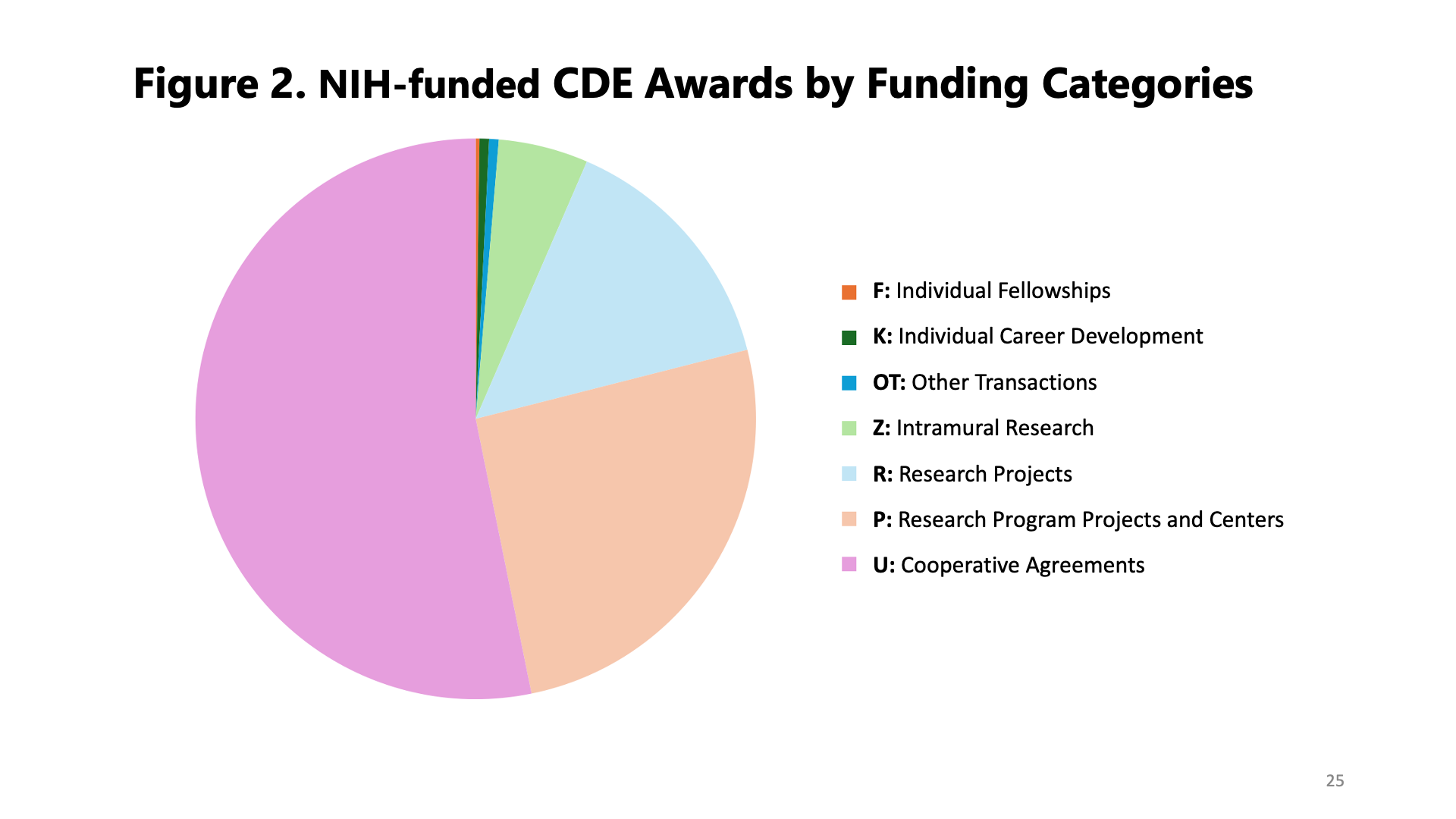
Finally, regarding publications, the GenAI analysis validated our hypothesis that most of the CDE publications primarily focused on the application of CDEs in clinical and translational research. The next most prominent areas included publications on developing and vetting CDEs—which highlighted collaborative and iterative processes involving expert review and public feedback—and standardization and harmonization—which focused on aligning CDEs across domains to support consistent data collection and integration of datasets.
Although the current body of literature offers a strong foundation demonstrating the value of CDEs, including their applications in AI and machine learning, this remains a rapidly evolving field. Some other emerging areas of focus are the use of CDEs in community research and strategies for reusing existing CDEs. Ongoing research is needed to address emerging challenges and to broaden the adoption and impact of CDEs across diverse research settings.
To that last point, the ODSS team continues to refine our GenAI analysis. In response to our findings, we have identified key lessons organized into a “Three C’s” framework to promote the adoption and use of CDEs.
First, foster more collaborations between Institutes and Centers within NIH that prompt researchers to use CDEs for better data sharing. Second, establish a community of practice around CDE usage that helps pool insights and build research capacity. Third, communicate about CDEs to raise awareness and provide strategies that promote CDE adoption.
Additionally, the ODSS team recognized the potential GenAI tools hold in achieving more with fewer resources, enabling teams to engage in smarter, more efficient meta-analysis of large data sets. This analysis marked an important first step in harnessing AI’s full potential for data science at NIH. Now, we are looking at how we can leverage GenAI with other workflows, improving the scale and reusability of this emerging tool.
To learn more about CDEs you can visit the CDEs webpage on the ODSS website. You can learn more about NIH’s AI strategy by visiting the Office of Science Policy website.